I tried to beat XGBoost with a decision tree and a prompt. On fraud data, that’s a suicide mission.
Yandex Research disagrees. Dudarov & Prokhorenkova at Yandex Research built a method called Talking Trees that loops an LLM through a decision tree: audit, find one flaw, write the fix, repeat. On small UCI datasets, it works.
I ran it on two fraud datasets. It does not.
Method Glossary
| Method | Explanation |
|---|---|
| Talking Trees | Dudarov & Prokhorenkova’s agent loop that uses an LLM to inspect and rewrite a decision tree iteratively |
DecisionTreeClassifier | scikit-learn’s greedy CART implementation — we cap it at max_depth=5 with balanced class weights |
| XGBoost | A gradient boosting library that ensembles weak trees with regularization — the industry default for tabular fraud detection |
| CatBoost | Yandex’s gradient booster that handles categorical features natively — our second strong baseline |
| Kimi K2.6 | Moonshot AI’s large language model, accessed via OpenRouter, that acts as the tree-refinement agent |
| GPT-5.5 | OpenAI’s large language model that acts as an alternative agent to test reliability |
What Talking Trees Does
Talking Trees is an agent loop where an LLM interactively refines a DecisionTreeClassifier. The steps are:
- Train an initial tree on the training set.
- Prompt the LLM to inspect the fitted tree, find one specific improvement, and return Python code that implements it.
- Execute the code, evaluate on validation data, and keep the best tree seen so far.
- Repeat for a fixed number of steps.
The paper reports strong results on UCI benchmarks — often matching or beating gradient boosters on small datasets. The authors’ intuition is that LLM reasoning about feature interactions and split quality can discover trees that greedy CART misses.
The question is whether that intuition survives fraud data.
What I Changed
I started from the official Talking Trees repository1 and made the following modifications:
| Change | Reason |
|---|---|
| Added Kimi K2.6 support | The original code supports OpenAI and local models; I added simpleaichat backend for Kimi K2.6 via OpenRouter |
| Fixed categorical handling | My fraud-detection and ieee-cis datasets have mixed types; I added .astype(str) before tree inspection to prevent pd.Categorical serialization errors |
Removed simple-parsing dependency | It conflicted with my environment; I replaced it with direct argparse |
| Added fallback mechanism | If the LLM produces invalid code or times out, I fall back to the initial sklearn tree and log the failure |
| Metrics logging | I added per-run JSON output with train/val/test AUC, AP, Recall@1%FPR, tree depth, node count, and wall time |
All other hyperparameters match the paper: max_depth=5, class_weight='balanced', max 15 agent steps, ROC AUC as the optimization metric.
Setup
I benchmarked on two fraud datasets, three random seeds, two LLMs, and three baselines.
Kimi K2.6 is Moonshot AI’s model, accessed via OpenRouter. GPT-5.5 is OpenAI’s model. Both serve as the agent in the Talking Trees loop.
The baselines are sklearn’s DecisionTreeClassifier, XGBoost, and CatBoost. CatBoost is Yandex’s own gradient booster that handles categorical features natively.
The data:
ieee-cis— Kaggle fraud data, subsampled to N=1k/5kfraud-detection— Amazon FDB at N=500/1k/2k
I used seeds 42, 43, and 44, with a 60/20/20 stratified split. I subsampled to keep API costs manageable — a full-scale run would have cost hundreds of dollars per seed.
Results
Accuracy
I averaged test AUC across three random seeds for each configuration. The results:
| Model | Test AUC | vs Sklearn d5 | vs XGBoost | Fallback Rate | Time |
|---|---|---|---|---|---|
| Kimi K2.6 | 0.676 ± 0.058 | +0.041 | −0.094 | 40% (6/15) | 184s |
| GPT-5.5 | 0.657 ± 0.061 | +0.035 | −0.113 | 7% (1/15) | 80s |
| Sklearn d5 | 0.634 ± 0.148 | — | −0.136 | 0% | <0.1s |
| XGBoost | 0.770 ± 0.088 | +0.136 | — | 0% | <1s |
| CatBoost | 0.774 ± 0.077 | +0.140 | +0.004 | 0% | <1s |
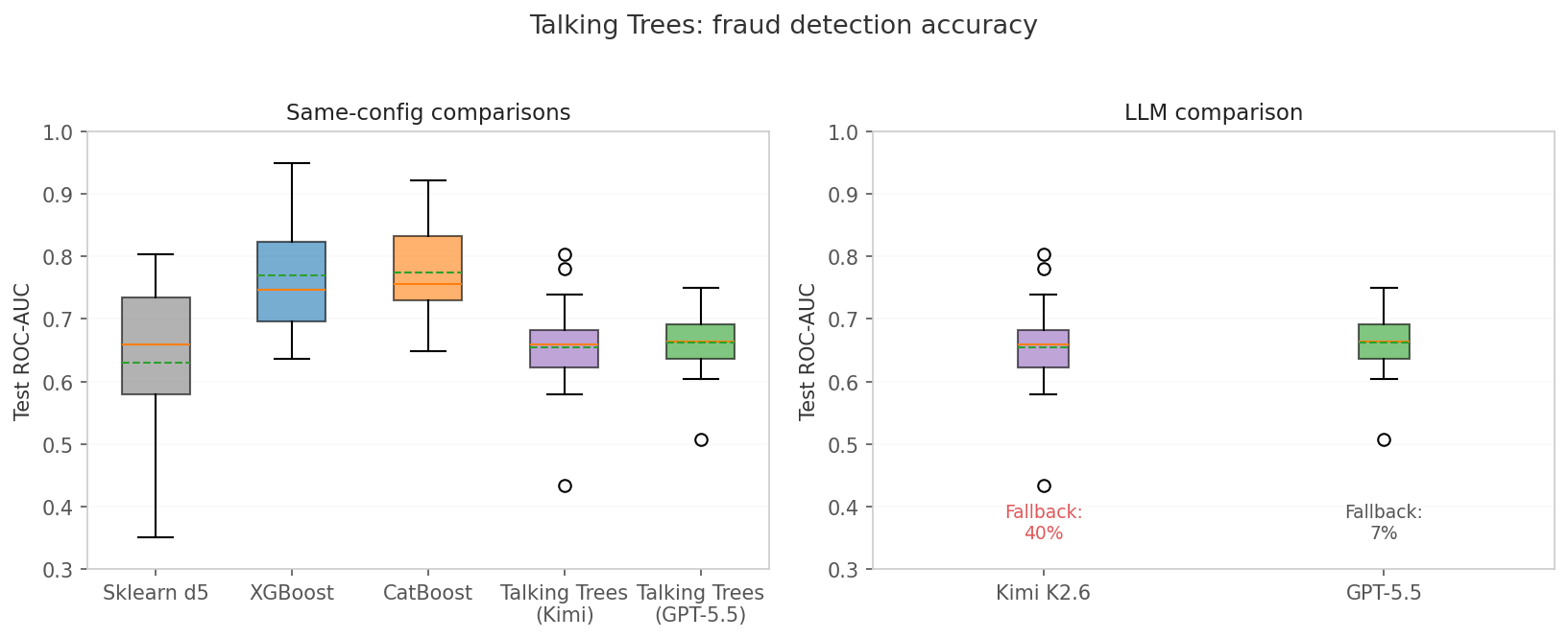
The left panel shows direct same-config comparisons. Talking Trees edges out sklearn d5 but is crushed by gradient boosters. The gap is not marginal — it is roughly 10 percentage points of AUC, which in fraud detection is the difference between a usable model and a random guesser.
The right panel compares the two LLMs. Kimi achieves higher peak accuracy but fails on 40% of runs, falling back to the initial tree. GPT-5.5 is more reliable — only 7% fallback — but slightly less accurate on average.
Generalization Gap
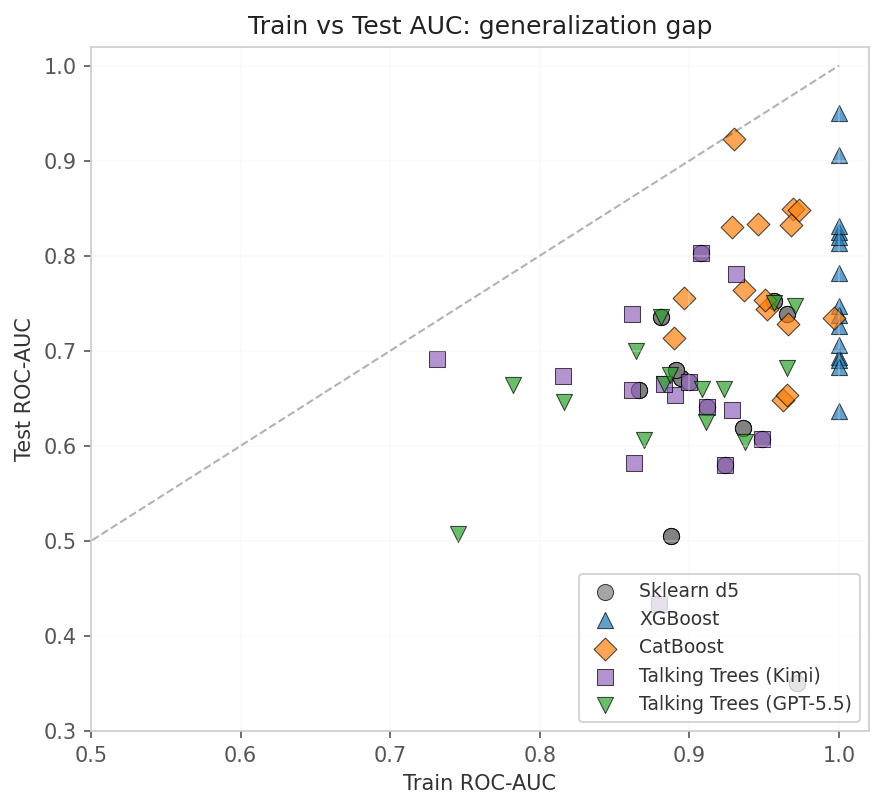
The diagonal on the plot marks perfect generalization. Points below it are overfitting. Talking Trees clusters far below the diagonal.
I computed the train-test gap by subtracting test AUC from train AUC for each run, then averaging:
- Kimi: train-test gap = 0.187
- GPT-5.5: train-test gap = 0.231
- sklearn d5: train-test gap ≈ 0.05 — typical for depth-5 trees
- XGBoost: train-test gap ≈ 0.08
The LLM fine-tunes splits to the training data. It creates thresholds that separate the training set beautifully but do not generalize. This makes sense — the LLM is optimizing validation AUC at each step, but the tree structure it produces memorizes training patterns rather than learning robust decision boundaries.
Cost Analysis
I estimated cost by counting tokens per API call at roughly $0.03–0.05 per call and 5–15 steps per run:
| Model | Cost/run | Δ vs sklearn | Cost per +0.01 AUC | Δ vs XGB |
|---|---|---|---|---|
| Kimi | ~$5 | +0.041 | $1.22 | −0.094 |
| GPT-5.5 | ~$3 | +0.035 | $0.86 | −0.113 |
| XGBoost | $0 | +0.136 | $0 | — |
The economics are brutal. Talking Trees costs dollars per run for a modest improvement over sklearn. XGBoost costs nothing and delivers +0.11 AUC more than Talking Trees.
I got the cost-per-0.01-AUC figure by dividing the total run cost by the AUC improvement over sklearn d5. Even if you only care about beating sklearn d5, that ratio is $0.86–1.22. For a production pipeline scoring millions of transactions, that is unaffordable. The fallback rate means two in five Kimi runs are wasted entirely.
Why Fraud Data Breaks the Method
The paper reports strong results on UCI datasets. Fraud data breaks the method for four reasons.
High dimensionality. The ieee-cis dataset has 455 features after minimal preprocessing — far more than the UCI benchmarks. The LLM cannot reason about interactions in a 455-dimensional space from a text serialization of the tree.
Adversarial signal. Fraud patterns are deliberately hidden. Legitimate transactions look like fraud and vice versa. The LLM’s common sense about what makes a good split is actively misleading — it suggests splits that would separate obvious classes, but fraud is not obvious.
Overfitting to validation. The LLM optimizes val AUC at each step. On small val sets — 100–200 rows for our subsampled configs — this is noisy. The LLM chases spurious correlations and the tree memorizes them.
No regularization mechanism. Unlike gradient boosters — which use shrinkage, subsampling, and early stopping — Talking Trees has no way to penalize complexity. The tree grows to fit whatever the LLM suggests. The paper caps depth at 5, but even depth-5 trees can overfit badly when splits are chosen adversarially.
Practical Verdict
| Approach | Use Case | Verdict |
|---|---|---|
| Talking Trees for fraud | Production scoring | ❌ No — too slow, too unreliable, too expensive |
| Talking Trees for fraud | Research / prototyping | ⚠️ Maybe — useful as a baseline or teaching tool |
| Talking Trees for UCI benchmarks | Paper replication | ✅ Yes — the authors’ results hold on their chosen data |
| XGBoost / CatBoost | Any fraud task | ✅ Start here — faster, cheaper, more accurate |
Raw Data
Analysis scripts and our fork of the original code are available on request — not published.
Conclusion
I spent $5 to generate a single decision tree that XGBoost beat by 10 percentage points in 0.1 seconds. Talking Trees looks like a breakthrough on paper, and on clean, small datasets, it actually works. It uses LLM reasoning to find splits that greedy algorithms miss, and the research results are legitimate.
But fraud detection is not a UCI benchmark. Between the adversarial signals and the extreme class imbalance, the core assumption of the method collapses. The LLM does not reason through the complexity — it just overfits and falls back.
The lesson here is not that LLMs cannot handle tabular ML. It is that LLM-guided methods are dangerously dataset-dependent. If your data is pristine, give it a shot.
If you are fighting fraud, stick with XGBoost.
My implementation is a fork of the official Talking Trees repository1 with modifications for Kimi K2.6 and my fraud datasets. Experiments run on airig2. GPU time and API credits funded by Maxime Guerreiro.
AMD 9900X + RTX 5090 ↩︎