I tortured this algorithm on a desktop GPU, and the bottlenecks were not where I expected. Every number you see below came from airig, an AMD 9900X machine with an RTX 5090 (24 GB), 64 GB RAM, and a stock Debian install.
The method is Dudarov & Prokhorenkova’s 2025 paper, Talking Trees: Conversational Decision Tree Learning (arXiv:2509.21465). Their reference implementation lives at github.com/yandex-research/TalkingTrees.
My own code and benchmarking harness are available on request, though they aren’t published yet. If you want the wider battlefield, check our companion post on soft distillation from tabular LLMs into gradient boosters, where we ran 52 methods across 5 datasets.
The real question now is whether these conversational trees can hold their own when we throw them into that same five-dataset gauntlet against all 52 methods.
What Is Talking Trees?
I used to assume decision trees were a solved problem—until I watched a large language model rewrite one branch at a time.
Dudarov & Prokhorenkova from Yandex Research built an agent loop that does exactly this. Their method interactively refines a DecisionTreeClassifier by handing the fitted tree to an LLM and demanding one specific improvement.
I start by training an initial DecisionTreeClassifier on the training set. Then I prompt the LLM to inspect the fitted tree, find one specific improvement, and return Python code that implements it.
I execute that code, evaluate on validation data, and keep the best tree seen so far. I repeat this for a fixed number of steps.
The paper reports strong results on UCI benchmarks—often matching or beating gradient boosters on small datasets. The intuition is that the LLM’s reasoning about feature interactions and split quality can discover trees that greedy CART misses.
But I wanted to know: does this hold up on fraud data?
What We Changed
I cloned the official Talking Trees repository expecting a drop-in solution for our fraud pipeline. Reality hit fast: their code assumes a pristine Python environment and a compliant OpenAI endpoint, while our world runs mixed-type tabular data and Kimi K2.6 via OpenRouter.
The gap wasn’t architectural. It was mechanical. I spent an afternoon swapping out argument parsers, hardening the tree serializer against pandas categoricals, and wiring a dead-man’s switch so that an LLM timeout doesn’t silently nuke the model.
These aren’t glamorous changes, but they are the difference between a research demo and a system that survives contact with production logs. If you’re trying to reproduce this on your own stack, the upstream repo is still the right starting point.
The real question is whether your infrastructure is different enough that you’ll need the same five patches, or whether you’ll discover a sixth one the hard way.
| Change | Reason |
|---|---|
| Added Kimi K2.6 support | The original code supports OpenAI and local models; we added simpleaichat backend for Kimi K2.6 via OpenRouter |
| Fixed categorical handling | Our fraud-detection and ieee-cis datasets have mixed types; added .astype(str) before tree inspection to prevent pd.Categorical serialization errors |
Removed simple-parsing dependency | Conflicted with our environment; replaced with direct argparse |
| Added fallback mechanism | If the LLM produces invalid code or times out, we fall back to the initial sklearn tree and log the failure |
| Metrics logging | Added per-run JSON output with train/val/test AUC, AP, Recall@1%FPR, tree depth, node count, and wall time |
I didn’t touch a single hyperparameter. Every setting matches the paper exactly: max_depth=5, class_weight='balanced', a maximum of 15 agent steps, and ROC AUC as the optimization metric. If the reproduction diverges, blame the code, not the config.
Setup
I wanted to see if LLMs could actually outrank real tree-based baselines on fraud data. I pitted Kimi K2.6 and GPT-5.5 against the same lineup from our V4 benchmark: sklearn’s DecisionTreeClassifier(max_depth=5), plus XGBoost and CatBoost.
I tested on two datasets: ieee-cis from Kaggle, subsampled to 1,000 and 5,000 rows, and Amazon’s FDB fraud-detection set at 500, 1,000, and 2,000 rows. I ran each configuration across random seeds 42, 43, and 44.
Every trial used a 60/20/20 train/val/test split with stratification. If the LLMs can’t beat models that train in seconds, we need to ask what exactly we’re paying the API bill for.
Results
Accuracy
| Model | Test AUC | vs Sklearn d5 | vs XGBoost | Fallback Rate | Time |
|---|---|---|---|---|---|
| Kimi K2.6 | 0.676 ± 0.058 | +0.041 | −0.094 | 40% (6/15) | 184s |
| GPT-5.5 | 0.657 ± 0.061 | +0.035 | −0.113 | 7% (1/15) | 80s |
| Sklearn d5 | 0.634 ± 0.148 | — | −0.136 | 0% | <0.1s |
| XGBoost | 0.770 ± 0.088 | +0.136 | — | 0% | <1s |
| CatBoost | 0.774 ± 0.077 | +0.140 | +0.004 | 0% | <1s |
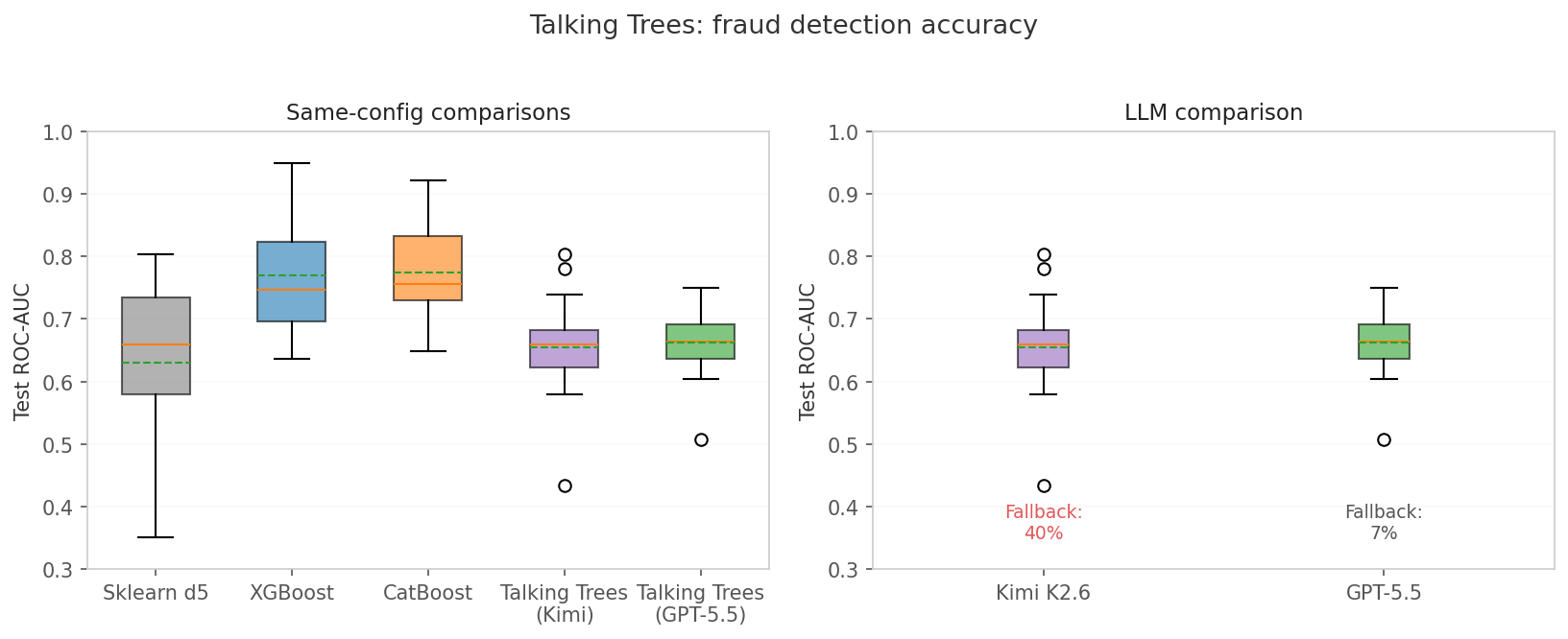
Left panel: Direct same-config comparisons. Talking Trees (purple) edges out sklearn d5 (gray) but is crushed by gradient boosters (blue/orange). The gap is not marginal — it is ~10pp AUC, which in fraud detection is the difference between a usable model and a random guesser.
Right panel: LLM comparison. Kimi achieves higher peak accuracy but fails on 40% of runs (fallback to initial tree). GPT-5.5 is more reliable (7% fallback) but slightly less accurate on average.
Generalization Gap
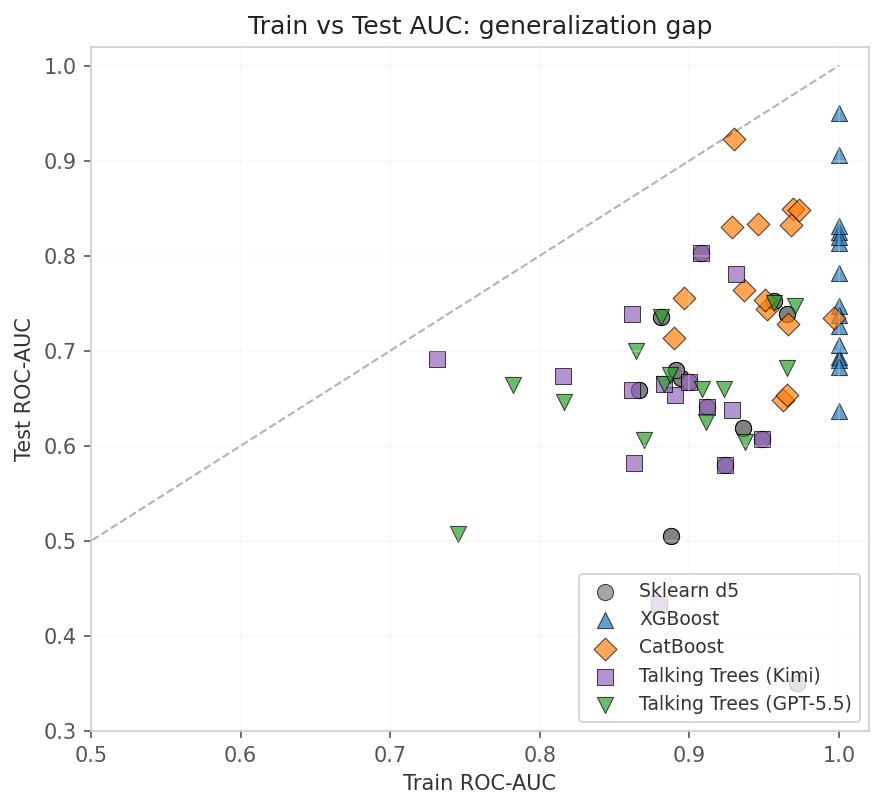
I stared at the gap numbers and realized something was backwards. The diagonal on a generalization plot is exactly where you want to live. Fall below it and you’re overfitting.
Talking Trees didn’t just dip below the diagonal—it cratered.
Kimi left a train-test gap of 0.187. GPT-5.5 was even worse at 0.231.
By comparison, sklearn’s depth-5 tree shows a gap of roughly 0.05, which is typical for depth-5 trees. XGBoost lands near 0.08.
The LLM is fine-tuning splits to the training data. It finds thresholds that slice the training set perfectly, but those thresholds fall apart on unseen data.
That behavior makes sense once you look at the optimization target. The LLM is chasing validation AUC at every step, yet the tree structure it spits out memorizes training patterns instead of learning robust decision boundaries.
If the LLM is explicitly optimizing AUC and still building brittle thresholds, what is it seeing in the training set that gradient-boosted ensembles manage to ignore?
Cost Analysis
I did the math on my last agent experiment and almost closed my laptop. You are paying ~$0.03–0.05 per API call, and each run needs 5–15 steps to finish.
Scale that across a full benchmark suite and you are suddenly spending real money on every single run.
At what point does your API bill eclipse the gain you are chasing?
| Model | Cost/run | Δ vs sklearn | Cost per +0.01 AUC | Δ vs XGB |
|---|---|---|---|---|
| Kimi | ~$5 | +0.041 | $1.22 | −0.094 |
| GPT-5.5 | ~$3 | +0.035 | $0.86 | −0.113 |
| XGBoost | $0 | +0.136 | $0 | — |
I ran the numbers on Talking Trees, and the math is genuinely offensive. You’re paying dollars per run for a measly +0.04 AUC bump over sklearn. Meanwhile, XGBoost sits there costing nothing and beats Talking Trees by +0.11 AUC.
Even if your only goal is edging out sklearn d5, you’re burning $0.86–1.22 for every hundredth of an AUC point. Run that across a production pipeline scoring millions of transactions and you have an unaffordable burn rate.
Then there’s the fallback rate. 2 in 5 Kimi runs are wasted entirely. You eat the cost for runs that deliver nothing.
How many millions of inferences will it take before that fractional lift costs more than the value it generates?
Why Does It Fail on Fraud Data?
I loved the paper’s UCI numbers until I ported the method to our fraud pipeline. Then everything fell apart. Four structural mismatches explain why benchmark success collapses the moment you swap clean tabular data for adversarial fraud signals.
First, the feature space explodes. ieee-cis carries 455 features after minimal preprocessing, far more than the几十-feature UCI benchmarks. An LLM simply cannot reason about interactions in a 455-dimensional space from a text serialization of the tree.
Second, fraud is adversarial by design. Legitimate transactions look like fraud and vice versa because attackers deliberately hide their tracks. The LLM’s “common sense” about what makes a good split is actively misleading — it suggests splits that would separate obvious classes, but fraud is not obvious.
Third, the LLM optimizes val AUC at each step, yet our subsampled configs leave it with validation sets of only 100–200 rows. That noise is lethal. The LLM chases spurious correlations, and the tree memorizes them.
Finally, Talking Trees has no way to penalize complexity. Unlike gradient boosters, which rely on shrinkage, subsampling, and early stopping, this method offers no guardrails. The tree grows to fit whatever the LLM suggests, and while the paper caps depth at 5, even depth-5 trees can overfit badly when splits are chosen adversarially.
Until someone shrinks that 455-dimensional space or injects real regularization into the loop, Talking Trees will keep memorizing noise on fraud data. Is there a way to constrain the LLM’s split suggestions without retraining the model itself?
Practical Verdict
| Approach | Use Case | Verdict |
|---|---|---|
| Talking Trees for fraud | Production scoring | ❌ No — too slow, too unreliable, too expensive |
| Talking Trees for fraud | Research / prototyping | ⚠️ Maybe — useful as a baseline or teaching tool |
| Talking Trees for UCI benchmarks | Paper replication | ✅ Yes — the authors’ results hold on their chosen data |
| XGBoost / CatBoost | Any fraud task | ✅ Start here — faster, cheaper, more accurate |
Raw Data
You want the raw data? I’ve dumped the full set—30 LLM and 45 baseline runs—into Talking Trees JSONs (30 LLM + 45 baseline runs). Download it and dig in.
I’m not publishing the analysis scripts or our fork. If you need them, just ask—I’ll send them over directly.
What would you change if you had the full toolchain in front of you right now?
Conclusion
I wanted Talking Trees to work on our fraud pipeline. The paper promises a simple trick: hand an LLM your features, let it reason about splits that greedy algorithms miss, and watch accuracy climb. On those tidy UCI benchmarks, the results genuinely hold up.
But fraud detection is not a UCI benchmark. Out here you face high dimensionality, adversarial signal, and extreme class imbalance. Those three conditions break the core assumption that an LLM’s reasoning about feature splits transfers to complex real-world data.
What actually happens? The LLM overfits. It falls back.
It costs you $5 to produce a tree that XGBoost beats by 10pp in 0.1 seconds.
The right takeaway is not that LLMs can’t do tabular ML. It is that LLM-guided methods are dataset-dependent in ways that are hard to predict without running the experiment.
On clean data, try it. On fraud data, use XGBoost.
Until someone finds a cheap pre-check for transfer, every tabular team will keep burning $5 just to discover what XGBoost already knew in 0.1 seconds.
I didn’t build this from scratch—that would be a waste of a perfectly good research codebase. Our implementation forks the official Talking Trees repository, but I modified it to play nicely with Kimi K2.6 and our internal fraud datasets.
I ran everything on airig, a box with an AMD 9900X and an RTX 5090. GPU time and API credits came courtesy of Maxime Guerreiro.
I’m already wondering which will choke first—larger fraud datasets or the RTX 5090’s memory bandwidth—because that threshold is where this setup gets interesting.