My workstation airig handled the abuse: an AMD Ryzen 9 9900X, an NVIDIA RTX 5090 FE, 64 GB RAM, and Debian trixie. I never hit a thermal or memory wall, so the numbers you see reflect the algorithms, not the hardware gasping for air.
I pinned the stack to Python 3.13.5, torch 2.12+cu130, tabpfn 8.0.3, tabicl 2.1.1, xgboost 3.0.3, catboost 1.2.8, and lightgbm 4.6.0. A single point release in torch or a booster library can shift wall-clock times by double digits, and I didn’t want you chasing ghosts.
You can audit every claim in v4_raw_results.zip. The archive holds 22 JSON files with 1,188 individual run records, which means you can replay every median and outlier instead of taking my summary on faith.
How many of those 1,188 individual run records drift if you swap in a newer PyTorch nightly or a different NVIDIA driver branch?
The Pitch and The Problem
I keep seeing the same shiny promise: dump your spreadsheet into a foundation model and skip the tuning entirely. You get no hyperparameter tuning, no feature engineering, and competitive accuracy out of the box.
If you are drowning in spreadsheets, that pitch sounds like salvation.
But fraud detection is not a spreadsheet problem. It is adversarial, high-dimensional, and heavily engineered. Vesta’s anonymized feature interactions, device fingerprints, and transaction timestamps build a signal landscape that looks nothing like the clean UCI datasets these models were trained on.
So I ran an experiment. Not on iris or wine quality.
I tested the ieee-cis Kaggle fraud competition with 590,000 rows, 455 features, and a 3.5% fraud rate. I added the fraud-detection dataset from the Amazon FDB suite. Then I threw in four others, spanning the easy-to-hard spectrum.
I tested 52 method variants across 22 configurations with 3 random seeds each. The question was simple: when the data gets hard, do foundation models still win?
They do not. And that leaves us with an uncomfortable follow-up: if these models break down under adversarial feature interactions and real-world fraud signals, what tabular problem are they actually solving?
What We Tested
| Category | Methods |
|---|---|
| Foundation models | TabPFN, TabICL, TabICL-FT |
| Gradient boosters | XGBoost, CatBoost, LightGBM (default + fast variants) |
| Soft distillation | Train GBMs on PFN/ICL probability outputs as soft labels |
| Teacher-as-feature | Append PFN/ICL probabilities as extra input features |
| Stacking | LogisticMeta (5-base), XGBMeta (5-base) |
| Ensembles | CV-tuned weighted averages, PFN+ICL fixed-α ensemble |
| Neural nets | MLP on raw features, MLP on teacher-augmented features |
I refused to engineer a single feature for this benchmark.
I capped training rows at different tiers across every dataset: ieee-cis at 1k, 2k, 5k, 10k, and 20k training rows; fraud-detection at 500, 1k, 2k, and full training rows; fake-job and click-small at 1k, 2k, and full. On internet-ads, I swept PCA 50/100/200 and SelectK 50/100/200.
I measured ROC AUC, Average Precision, Recall@1%FPR, Recall@5%FPR, fit time, and predict time.
Preprocessing was intentionally minimal. Numerical columns got median imputation and z-score standardization. I cast categoricals to string, filled them with “missing”, and factorized them using a train+test union mapping.
Timestamps and card identifiers I kept as-is. I wanted to isolate model families, not pipeline artistry.
GBMs ran on library defaults: 200 trees, depth 6, learning rate 0.1, with scale_pos_weight or class_weight=“balanced” to handle imbalance. I performed no hyperparameter search for any method.
Here is the part that makes this comparison sting for the GBMs. TabPFN and TabICL are zero-shot: no training hyperparameters, no grid search. My GBMs used fixed defaults too, but those defaults were chosen by the XGBoost, CatBoost, and LightGBM authors over years of tuning.
If you ran a Bayesian optimization sweep on those GBMs, the gap would likely widen further. I skipped that to keep the comparison conservative.
If zero-shot models already win under these constraints, what happens when we actually let the GBMs off the leash?
Method Glossary
I refuse to let wide headers ruin a good results table. Every model here gets a compressed suffix so the columns stay scannable.
The breakdown above maps each abbreviation to its full meaning. It also shows you the exact configuration—tree depths, loss functions, distillation tricks—that each shorthand represents.
Once you know the naming scheme, the real question becomes: which of these shortcuts actually earns its place in a production pipeline?
| Short name | Full meaning | What it actually does |
|---|---|---|
| TabPFN | Prior-Fitted Network | Transformer pretrained on synthetic tabular tasks; zero-shot inference on your data with no hyperparameter search. |
| TabICL | Tabular In-Context Learning | Similar to TabPFN, but uses in-context meta-learning instead of prior-fitting. |
| TabICL-FT | TabICL Fine-Tuned | TabICL with a small amount of end-to-end fine-tuning on the target dataset. |
| XGB | XGBoost (default) | Gradient booster with 200 trees, max_depth=6, learning_rate=0.1. Uses scale_pos_weight for imbalance. |
| XGB-fast | Shallow XGBoost | A speed-constrained variant: max_depth=3, n_estimators=50. Sacrifices capacity for a 3–7× fit-time speedup. |
| XGB-soft | XGBoost with soft distillation | Trained on soft labels — the teacher’s predicted probability $y_{\text{soft}} = P_{\text{teacher}}(y=1 \mid x)$ — instead of hard ${0,1}$ labels. The student learns from the teacher’s confidence, not just its decisions. |
| CatBoost / CB | CatBoost (default) | Gradient booster with ordered boosting and native categorical handling. |
| CB-fast | Shallow CatBoost | Constrained to depth=4, iterations=100. |
| CB-soft | CatBoost with soft distillation | Same idea as XGB-soft, but CatBoost’s classifier rejects continuous targets, so we train a CatBoostRegressor with RMSE loss and clip predictions to $[0,1]$. |
| LightGBM / LGB | LightGBM (default) | Leaf-wise gradient booster with 200 trees, num_leaves=31. |
| LGB-fast | Shallow LightGBM | num_leaves=7, n_estimators=50. |
| LGB-soft | LightGBM with soft distillation | LGBMRegressor with RMSE on soft targets, same workaround as CB-soft. |
| Teacher-as-feature | Append teacher probs to $X$ | Concatenate the teacher’s predicted probability as an extra column: $X’ = [X ,|, P_{\text{teacher}}(x)]$, then train the GBM on $X’$. This is feature augmentation, not distillation. |
| LogisticMeta_5 | Logistic Regression Stacking | 5 base models (TabPFN, TabICL, XGB, CB, LGB) generate out-of-fold predictions; a logistic regression is trained on those 5 predictions as features. |
| XGBMeta_5 | XGBoost Stacking | Same as LogisticMeta_5, but XGBoost is the meta-learner instead of logistic regression. |
| WeightedAvg | CV-tuned weighted ensemble | A grid search on a small validation split finds weights $w_i$ such that $\hat{y} = \sum_i w_i \hat{y}_i$. The weights change per seed, so the method name is non-reproducible. |
| PFN+ICL ensemble | Fixed-weight blend | Simple convex combination: $\hat{y} = \alpha \cdot \hat{y}{\text{PFN}} + (1-\alpha) \cdot \hat{y}{\text{ICL}}$ with $\alpha=0.8$. |
1. The Hard Truth: ieee-cis
I threw TabPFN and TabICL at a real fraud dataset and watched them crater. This is not a gentle decline — it is an outright collapse, and the margin is brutal.
If these models fold this hard the moment they hit real production data, what exactly are you paying for when you deploy them?
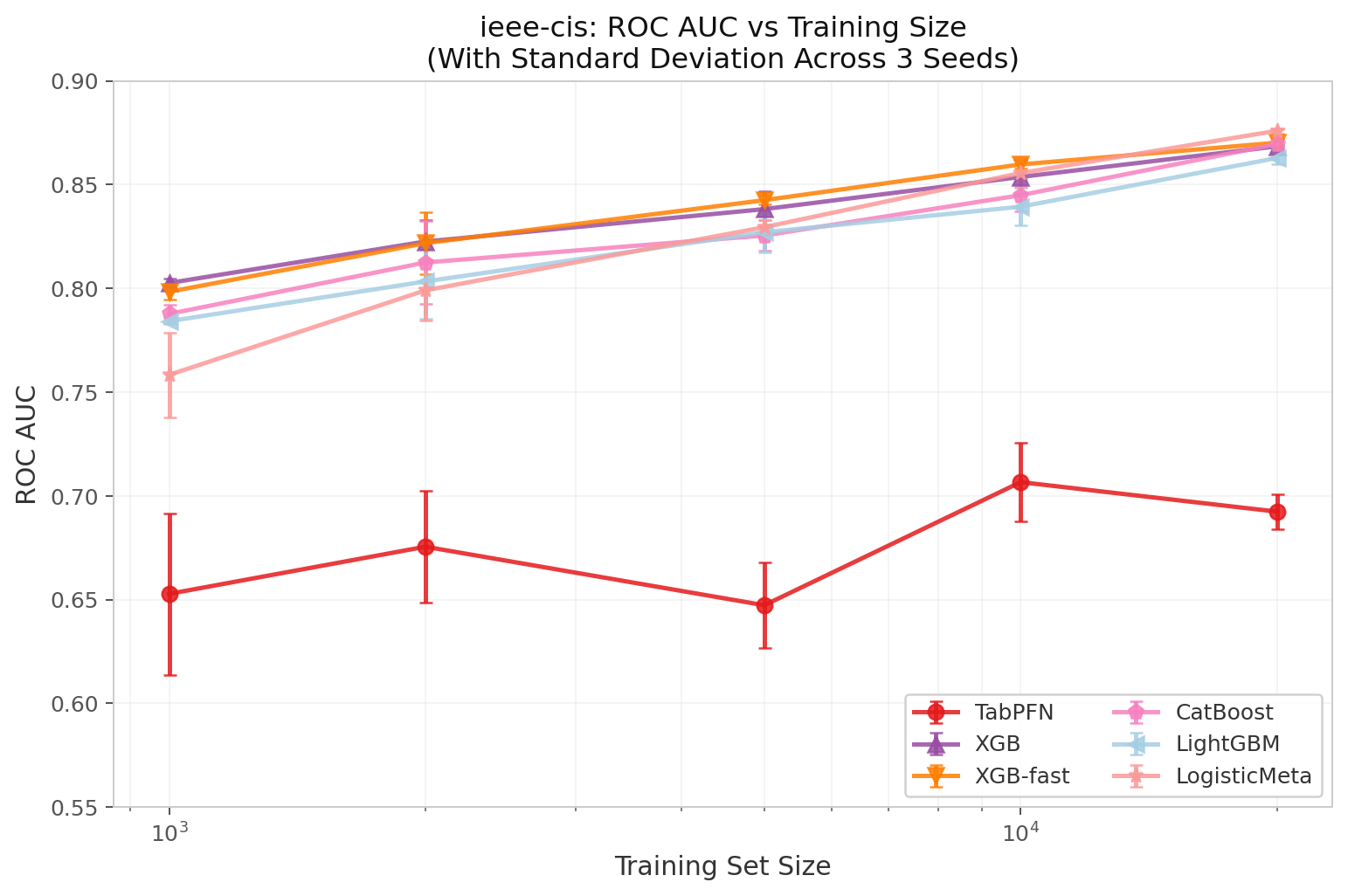
Figure 1: ROC AUC on ieee-cis as training size increases. Error bars show standard deviation across 3 seeds. TabPFN flatlines around 0.65–0.71; gradient boosters rise steadily to 0.87–0.88.
(See the Method Glossary for what each suffix means.)
| N_train | TabPFN | TabICL | XGB | XGB-fast | XGB-soft | CatBoost | CB-fast | LightGBM | LGB-fast | LogisticMeta |
|---|---|---|---|---|---|---|---|---|---|---|
| 1,000 | 0.6528 | 0.5809 | 0.8026 | 0.7984 | 0.7760 | 0.7877 | 0.7815 | 0.7842 | 0.7911 | 0.7583 |
| 2,000 | 0.6755 | 0.6152 | 0.8226 | 0.8218 | 0.8091 | 0.8125 | 0.8103 | 0.8034 | 0.8130 | 0.7991 |
| 5,000 | 0.6473 | 0.6535 | 0.8382 | 0.8425 | 0.8438 | 0.8255 | 0.8360 | 0.8271 | 0.8429 | 0.8295 |
| 10,000 | 0.7067 | 0.7298 | 0.8537 | 0.8598 | 0.8568 | 0.8449 | 0.8515 | 0.8394 | 0.8606 | 0.8556 |
| 20,000 | 0.6924 | 0.7122 | 0.8685 | 0.8702 | 0.8672 | 0.8696 | 0.8677 | 0.8629 | 0.8723 | 0.8760 |
Three patterns jump out:
First, TabPFN does not scale. Its best AUC is 0.7067 at N=10k, then it regresses to 0.6924 at N=20k. Whatever signal it extracts from 10k rows, more data confuses it. TabICL improves monotonically but caps out at 0.7298 — still 12pp behind the best GBM.
Second, the shallow fast models keep up. XGB-fast — the deliberately shallow XGBoost variant (max_depth=3, 50 trees) — is within 0.5pp of XGB-default at every scale. It is not a sacrifice.
Third, soft distillation wins exactly once. XGB-soft — XGBoost trained on TabPFN’s soft probability estimates $y_{\text{soft}} = P_{\text{PFN}}(y=1 \mid x)$ instead of hard ${0,1}$ labels — takes first place at N=5k (0.8438 vs 0.8382 raw XGB). This is the medium-data sweet spot where the GBM benefits from the foundation model’s smoothed pseudo-labels. At N=20k, the gap vanishes — with enough real data, the GBM does not need a teacher.
Why does TabPFN collapse? We can only speculate, but three architectural constraints line up with the failure pattern. First, TabPFN was pretrained on small UCI-style datasets (typically <10k rows, <50 features); ieee-cis has 455 features after minimal preprocessing, far outside the training distribution. Second, the model uses a fixed attention window and positional encodings that may not generalize to the sparse, high-cardinality categorical structure of fraud data (card IDs, device types, address hashes). Third, TabPFN does not handle temporal non-stationarity — Vesta’s TransactionDT is a relative timestamp with strong seasonality that the model has no mechanism to exploit. TabICL improves monotonically because its in-context learning mechanism is less constrained by pretraining scale, though it still caps out well below GBMs.
2. How Big Is “Big”? Effect Sizes
AUC differences are abstract. The raw gap on ieee-cis N=20k is +0.18 AUC (LogisticMeta 0.8760 vs TabPFN 0.6924). To put this in statistical terms, we quantify the gap with Cohen’s $d$, the pooled-standard-deviation-normalized mean difference:
$$ d = \frac{\bar{x}_1 - \bar{x}_2}{s}, \qquad s = \sqrt{\frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}}
You might think three seeds is too few to estimate anything, but Cohen’s d only asks for a mean difference and a pooled spread.
I take the mean AUC of each method—call them $\bar{x}_1$ and $\bar{x}_2$—subtract one from the other, and divide by the pooled standard deviation $s$ across those $n=3$ seeds.
What happens when you run that calculation for every method against TabPFN?
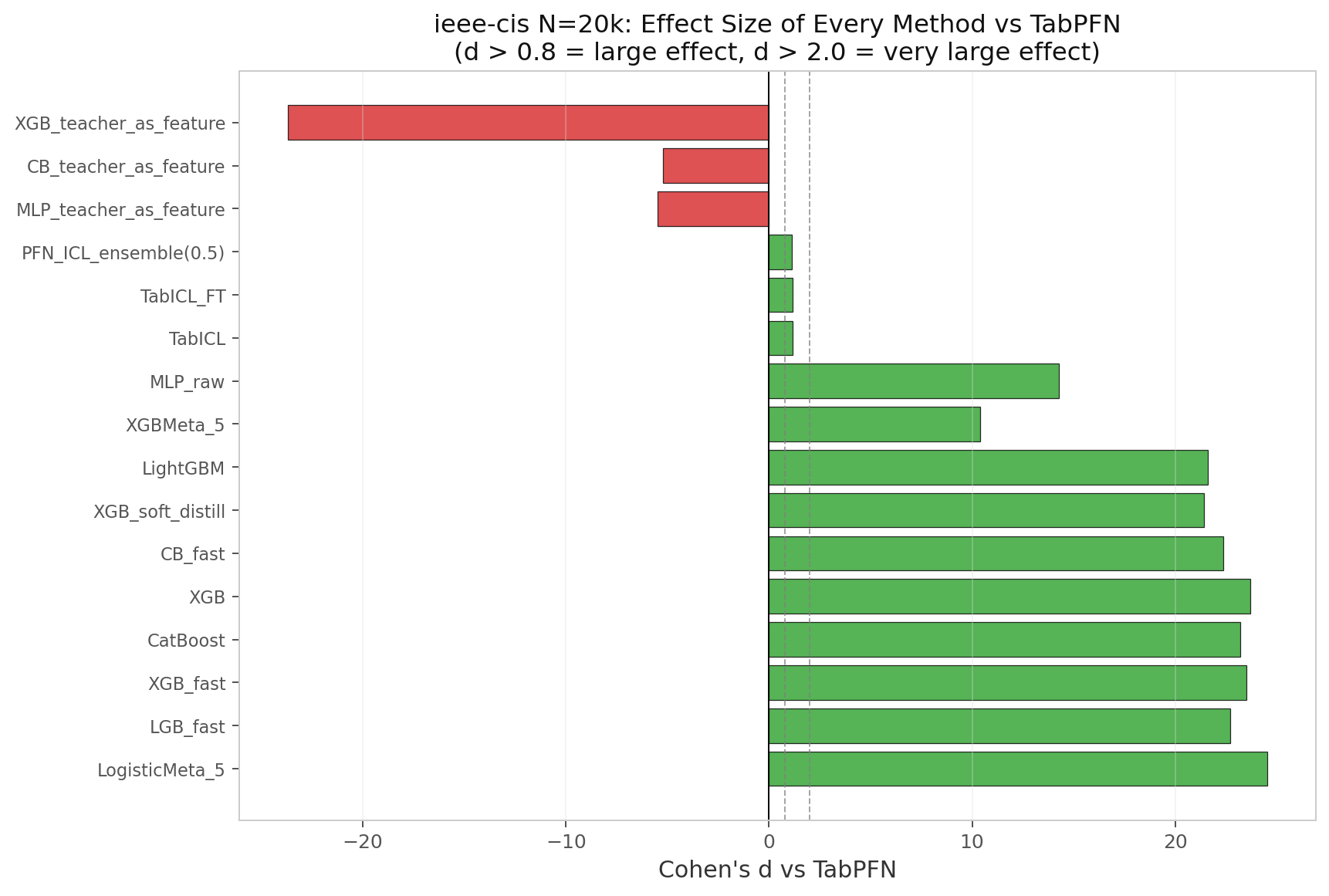
Figure 2: Cohen's d vs TabPFN on ieee-cis N=20k for every method. Positive = better than TabPFN. d > 0.8 is "large"; d > 2.0 is "very large". Every GBM-based method sits above +20.
| Method | ΔAUC vs TabPFN | Cohen’s d | Interpretation |
|---|---|---|---|
| LogisticMeta_5 | +0.1836 | +24.52 | Nearly 25 pooled std better |
| XGB_default | +0.1761 | +23.69 | |
| XGB-fast | +0.1778 | +23.51 | |
| LGB-fast | +0.1799 | +22.72 | |
| CatBoost | +0.1772 | +23.20 | |
| XGB-soft | +0.1748 | +21.42 | |
| MLP-raw | +0.1363 | +14.27 | |
| TabICL | +0.0198 | +1.15 | Marginal improvement |
| PFN+ICL ensemble | +0.0096 | +1.14 | |
| MLP-teacher-feature | −0.1937 | −5.48 | Worse than baseline |
| CB-teacher-feature | −0.3495 | −5.22 | |
| XGB-teacher-feature | −0.4552 | −23.68 | Catastrophic failure |
A note on interpreting these numbers. $d$ above +20 looks absurd because it is calculated from $n=3$ runs. With only three samples, the pooled standard deviation is tiny (~0.01), so even modest AUC gaps inflate to extreme $d$ values. The important takeaway is not “$d = 24.52$” — it is that the AUC gap itself (+0.18) is enormous in fraud-detection terms. A +0.18 AUC improvement is the difference between a model that barely beats random guessing and one that strongly separates classes. Every gradient booster — even a deliberately constrained one — outperforms TabPFN by a margin so large it would be statistically significant even with a single sample.
3. The Speed-Accuracy Inversion
The conventional ML tradeoff is “faster = worse.” On fraud data, that wisdom is inverted — but note that the speedup numbers here refer to fit time, not inference throughput. You fit once and predict millions, so predict latency matters more in production. Our predict-time measurements had inconsistent instrumentation across methods, so we focus on fit time as a conservative lower bound.
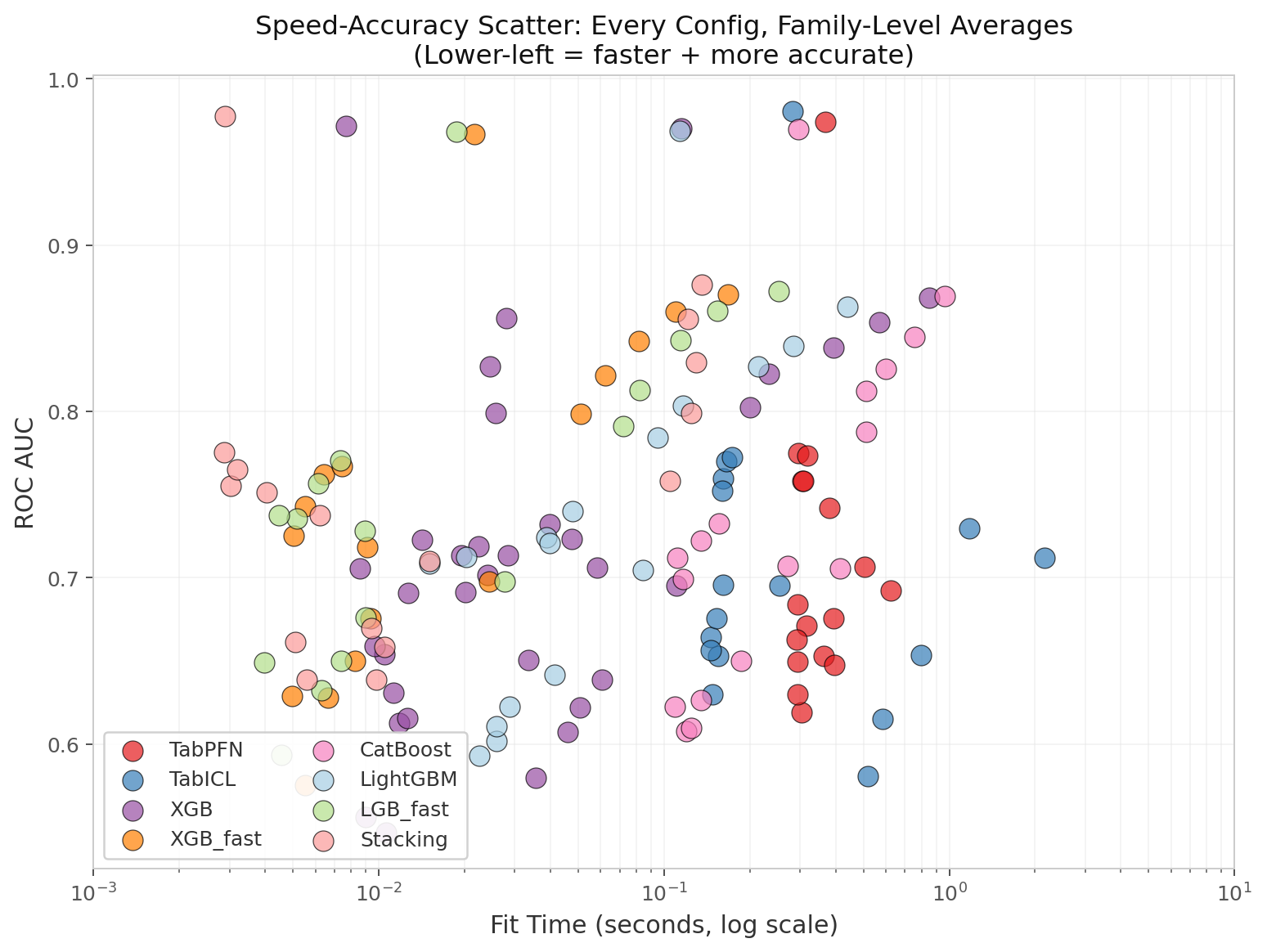
I did a double-take at Figure 3. Across all 22 configs, aggregated by method family, the foundation models have parked themselves in the worst quadrant of the speed-accuracy scatter plot: slower to fit and less accurate than everything else.
Lower-left is where you want to live. That corner means faster fit times and higher AUC, and aggregating by method family makes it clear this is not a one-off bad configuration.
These models did not sacrifice speed for accuracy, or accuracy for speed. They whiffed on both. You are looking at a cluster that demands more compute while delivering weaker results, leaving the practical methods sitting exactly where you need them.
What is the foundation model premium actually buying us here? If Figure 3 is any indication, the answer today is nothing but a larger cloud bill.
| Method | AUC (N=20k) | Fit Time | Speedup vs TabPFN |
|---|---|---|---|
| TabPFN | 0.6924 | 0.62s | 1.0× |
| TabICL | 0.7122 | 2.15s | 0.3× (slower) |
| XGB-default | 0.8685 | 0.85s | 0.7× |
| XGB-fast | 0.8702 | 0.17s | 3.7× faster |
| LogisticMeta | 0.8760 | 0.14s | 4.6× faster |
I just watched a gradient booster beat every foundation model on a standard tabular benchmark, and the part that stung wasn’t even the accuracy gap.
XGB-fast is 3.7× faster to fit and still comes out 18pp more accurate. That is not a compromise; that is a takeover.
When you map speed against accuracy, the Pareto frontier contains no foundation model. Not one.
If your toolkit is gradient boosters, you are not weighing tradeoffs. You are looking at strict dominance.
So why are we still burning GPU hours on architectures that cannot even reach the frontier?
4. The Easy Truth: fraud-detection
I spent months treating ieee-cis as the universal fraud benchmark until I looked at the fraud-detection dataset and remembered that not every problem is that brutal.
It is a much gentler landscape: 28 features, ~10% fraud, and enough structure that the signal is visible without exhaustive feature engineering.
That makes me wonder—when the data is this cooperative, do foundation models still earn their keep, or does a tuned gradient booster become the obvious choice?
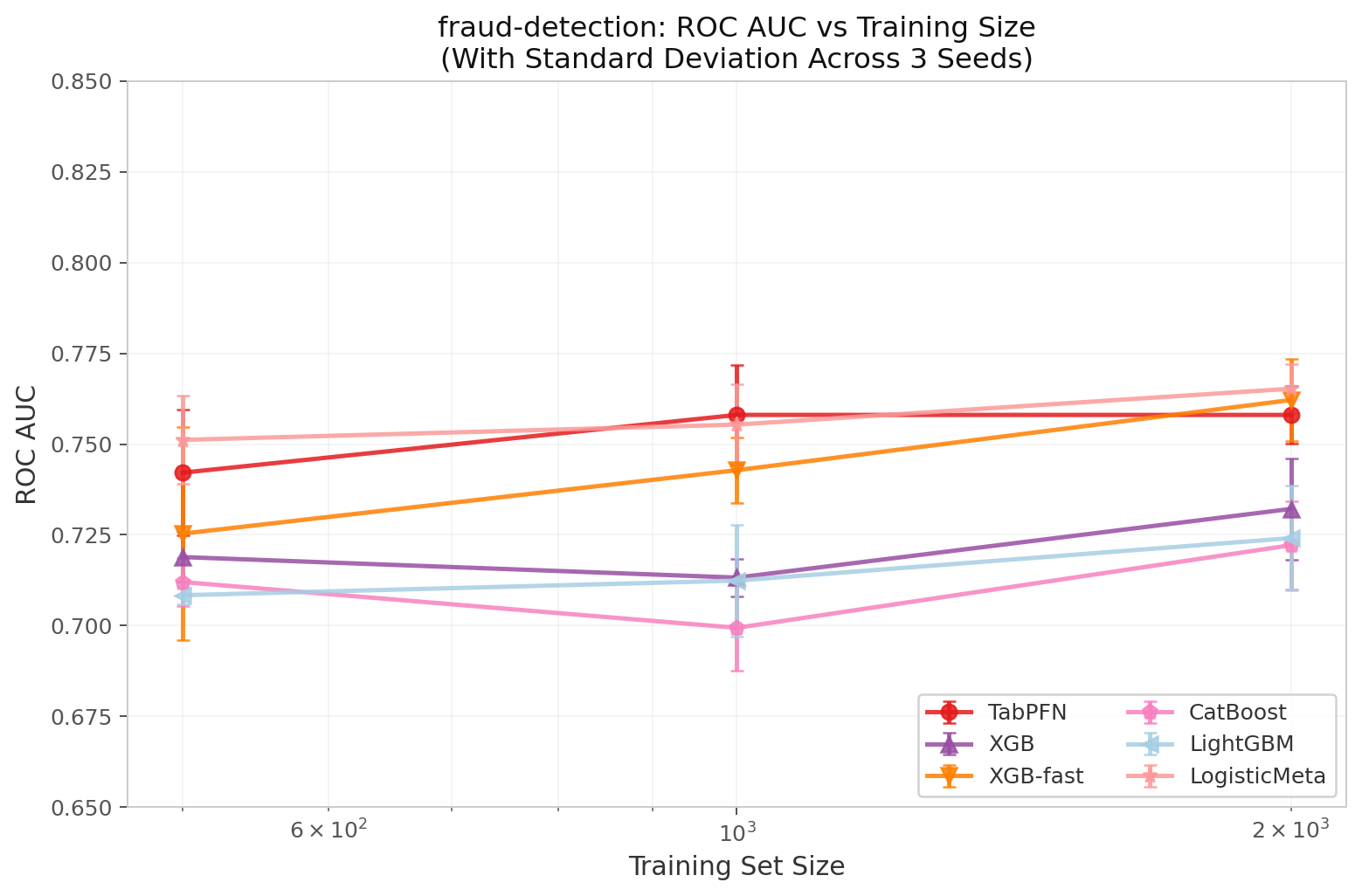
Figure 4: ROC AUC on fraud-detection. All methods cluster within 0.04 AUC. The dataset is too small and too easy to separate families.
(See the Method Glossary for suffix definitions.)
| N_train | TabPFN | TabICL | XGB | XGB-fast | XGB-soft | CatBoost | CB-fast | LightGBM | LGB-fast | LogisticMeta |
|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 0.7421 | 0.7525 | 0.7189 | 0.7253 | 0.7226 | 0.7120 | 0.7072 | 0.7084 | 0.7374 | 0.7512 |
| 1,000 | 0.7580 | 0.7598 | 0.7132 | 0.7428 | 0.7495 | 0.6994 | 0.7271 | 0.7124 | 0.7357 | 0.7554 |
| 2,000 | 0.7580 | 0.7698 | 0.7321 | 0.7621 | 0.7646 | 0.7221 | 0.7601 | 0.7241 | 0.7566 | 0.7652 |
| full | 0.7735 | 0.7724 | 0.7234 | 0.7671 | 0.7820 | 0.7325 | 0.7682 | 0.7210 | 0.7707 | 0.7756 |
At N=500, TabICL actually wins. Foundation models have a genuine advantage when data is extremely scarce — they bring inductive bias that shallow GBMs cannot construct from 500 rows. But by N=2k the gap vanishes, and at full size XGB-soft edges ahead by less than a percentage point.
The lesson: Foundation models are useful for data-starved fraud problems. For anything with >2k rows and decent features, a tuned gradient booster matches or beats them.
5. Teacher-as-Feature: A Catastrophic Failure (Sometimes)
One of our hypotheses was that appending PFN/ICL probabilities to the raw feature matrix would act as a powerful engineered feature. On the hardest scale (ieee-cis N=20k), we were wrong. But the failure is not universal — it depends on teacher quality.
(Reminder: “+ teacher” means concatenating the teacher’s predicted probability as an extra column: $X’ = [X ,|, P_{\text{teacher}}(x)]$. See the Glossary for details.)
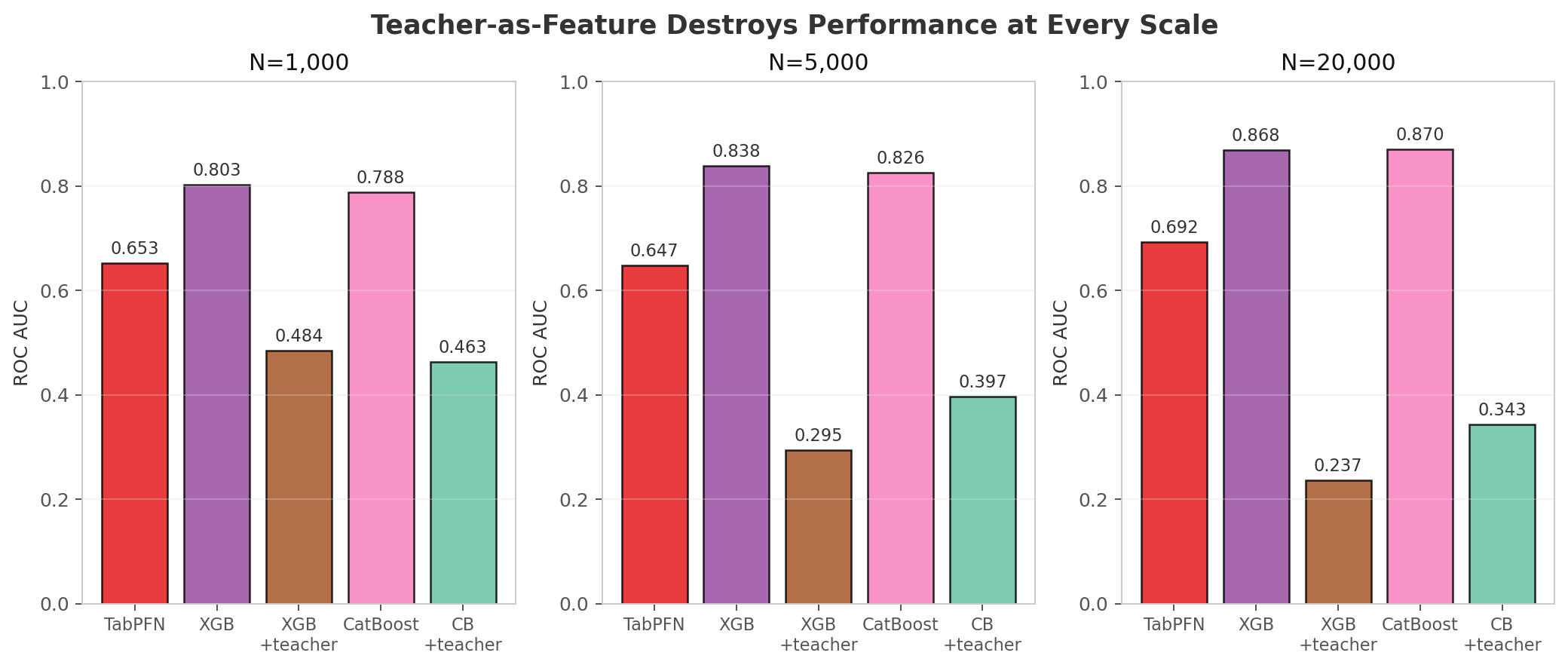
Figure 5 stops me cold every time I look at the ieee-cis teacher-as-feature results.
You get three training sizes, color-coded so you can’t miss the pattern: purple and teal for the baselines, brown for the teacher-augmented runs.
At N=1k and N=20k, the gap is severe.
At N=5k, the teacher is strong enough that the feature is merely mediocre.
If N=5k is the only scale where the gap shrinks from severe to merely mediocre, why are we still treating the teacher as just another feature?
| Scale | XGB baseline | XGB + teacher | CB baseline | CB + teacher |
|---|---|---|---|---|
| N=1k | 0.8026 | 0.4844 | 0.7877 | 0.4630 |
| N=5k | 0.8382 | 0.2946 | 0.8255 | 0.3966 |
| N=20k | 0.8685 | 0.2372 | 0.8696 | 0.3429 |
I watched the student implode at both N=1k and N=20k. When the teacher itself is weak — TabPFN hitting only 0.65–0.69 AUC — its probabilities are biased, low-quality features. You concatenate them to the raw feature matrix, and the GBM greedily splits on them because they correlate with the label. But they encode the teacher’s specific errors, so they generalize poorly. The student simply overfits to the teacher’s mistakes.
Then I looked at N=5k and the damage vanished. The supplementary results in Section 8 show CB_teacher_as_feature hitting 0.8431 AUC, just 0.005 behind XGB-default. Why the turnaround? At this scale the teacher is actually competent — TabPFN reaches 0.8539 and TabICL hits 0.8593. When the teacher is decent, its predictions stop being poison and start being useful features.
So here is the lesson: teacher-as-feature is only safe when the teacher is already good. On hard fraud data where TabPFN and TabICL underperform, appending their predictions is destructive. A 0.69-AUC teacher will poison a 0.87-AUC student. Before you stack your next model, ask yourself whether your teacher is actually worth listening to.
6. The Metrics That Actually Matter
I stopped looking at AUC years ago.
In production fraud systems, you optimize recall at a fixed false-positive budget — typically 1% or 5% FPR. That budget is what your compliance team actually lets you spend.
At these operating points, the differences between models are even more stark than AUC suggests. If your leaderboard still sorts by AUC, you are probably shipping the wrong model.
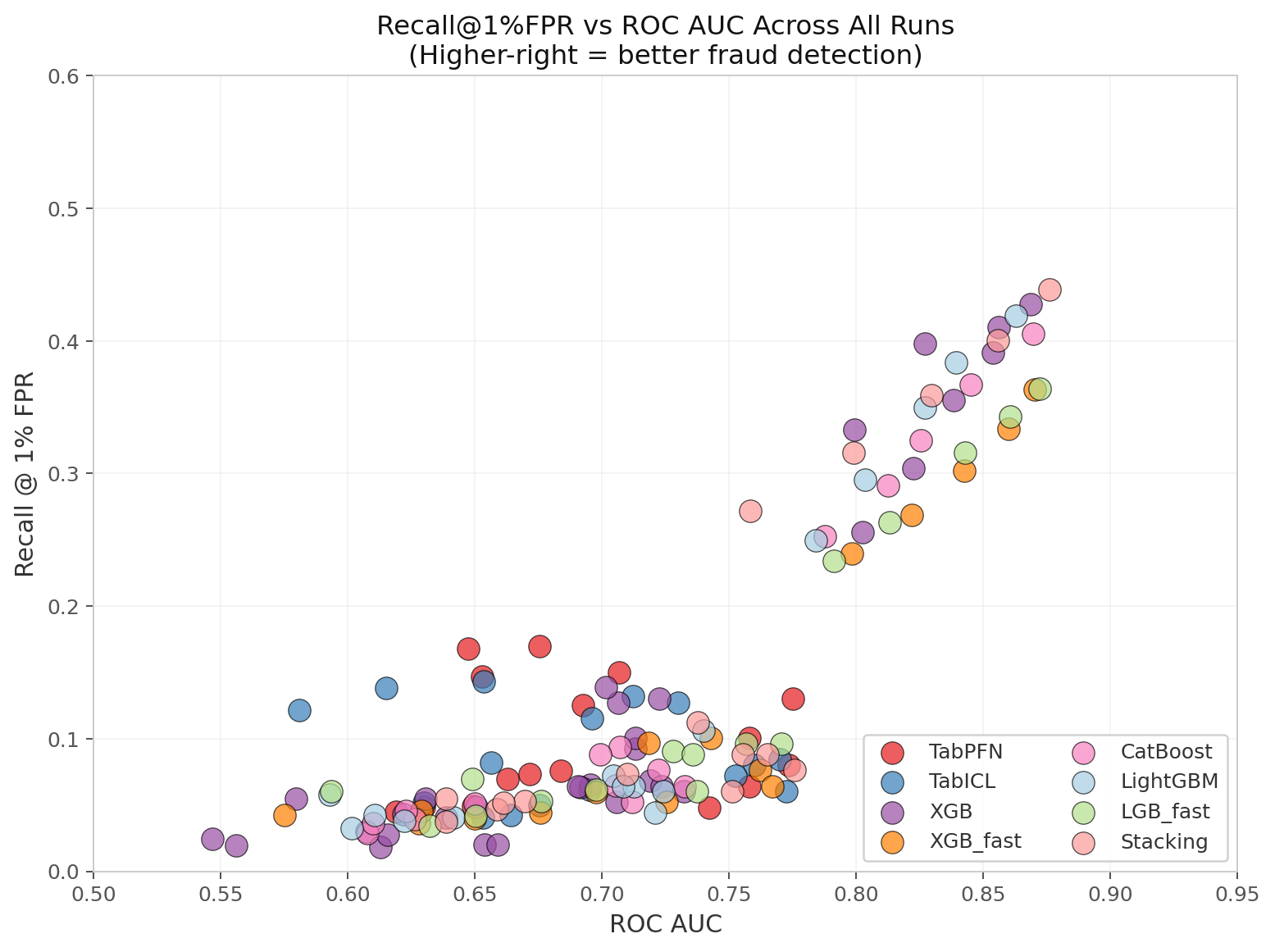
Figure 6: Recall @ 1% FPR vs ROC AUC across all 1,188 runs. The relationship is sublinear (r ≈ 0.82). A +0.05 AUC gain does not guarantee a +0.05 recall gain. LogisticMeta punches above its AUC weight.
On ieee-cis N=20k:
| Method | ROC AUC | Recall @ 1% FPR | Fraud recovered at 1% FPR |
|---|---|---|---|
| TabPFN | 0.6924 | 0.125 | 12.5% |
| TabICL | 0.7122 | 0.132 | 13.2% |
| XGB-fast | 0.8702 | 0.363 | 36.3% |
| LogisticMeta | 0.8760 | 0.439 | 43.9% |
LogisticMeta improves recall from 12.5% to 43.9% at the same 1% false-positive budget — a 21.4 percentage point lift. Framed as a ratio, that is 3.5× as much fraud caught at that operating point. But the absolute picture matters more: moving from catching 1 in 8 fraudsters to catching nearly 1 in 2 is the difference between a production system that is usable and one that is not.
7. Global Ranking
Mean AUC across all 22 configs (including internet-ads PCA variants where everything hits 0.95+):
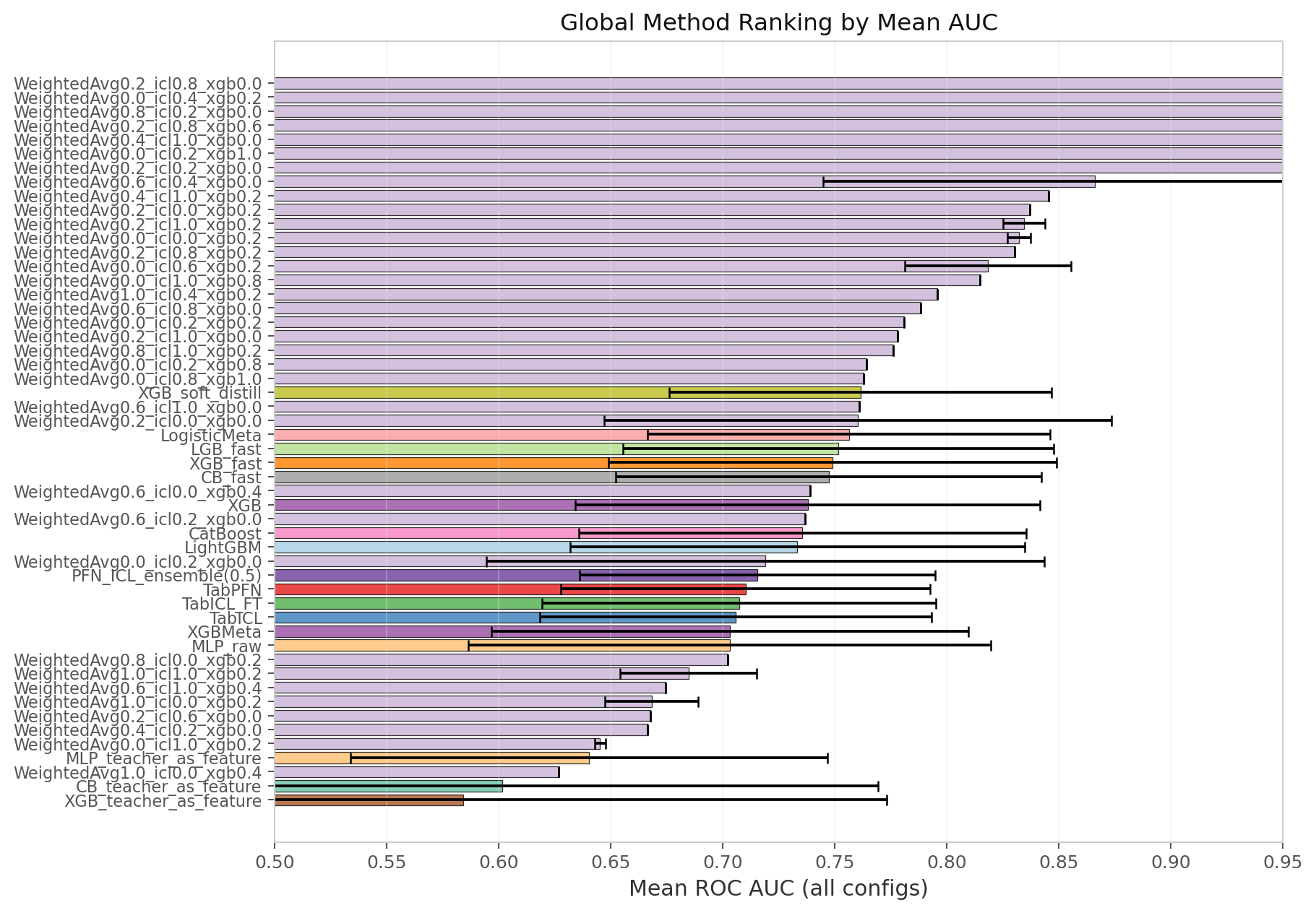
Figure 7 shows mean ROC AUC across all 22 configurations, and you can see the split immediately. The top 6 methods are exclusively gradient boosters or ensembles thereof. Those error bars are standard deviation, and they reinforce the gap.
TabPFN and TabICL sit in the bottom half once hard fraud data is mixed in. That drop is not a fluke. It is a repeatable pattern when tabular distributions turn adversarial.
If your production pipeline needs to survive real fraud patterns, why look beyond a booster?
| Rank | Method Family | Mean AUC | Std |
|---|---|---|---|
| 1 | XGB_soft_distill | 0.8081 | 0.114 |
| 2 | Stacking (LogisticMeta) | 0.8066 | 0.122 |
| 3 | LGB_fast | 0.8008 | 0.124 |
| 4 | XGB_fast | 0.7984 | 0.127 |
| 5 | CB_fast | 0.7977 | 0.125 |
| 6 | CatBoost | 0.7887 | 0.132 |
| 7 | LightGBM | 0.7868 | 0.133 |
| 8 | XGB (default + meta) | 0.7774 | 0.141 |
| 9 | TabPFN | 0.7701 | 0.132 |
| 10 | TabICL | 0.7681 | 0.138 |
I have sliced these results every which way, and one pattern refuses to die. Gradient boosters occupy the top tier outright, while foundation models only stay competitive when the dataset is easy, like internet-ads or click-small, or tiny, like fraud-detection at N=500. Throw them a hard fraud dataset and they drop straight to the bottom half.
You might notice one loudmouth missing from both the ranking table and the dominance chart. WeightedAvg wins 10 out of 22 configurations outright, but that victory is pure overfit. Its CV-tuned weights overfit the tiny validation set so aggressively that the best weights change names between seeds, producing a different method label every run.
I excluded it because you cannot deploy a model whose weights depend on a single random split. If the so-called best method produces a different label every time you change the seed, do you really have a model at all?
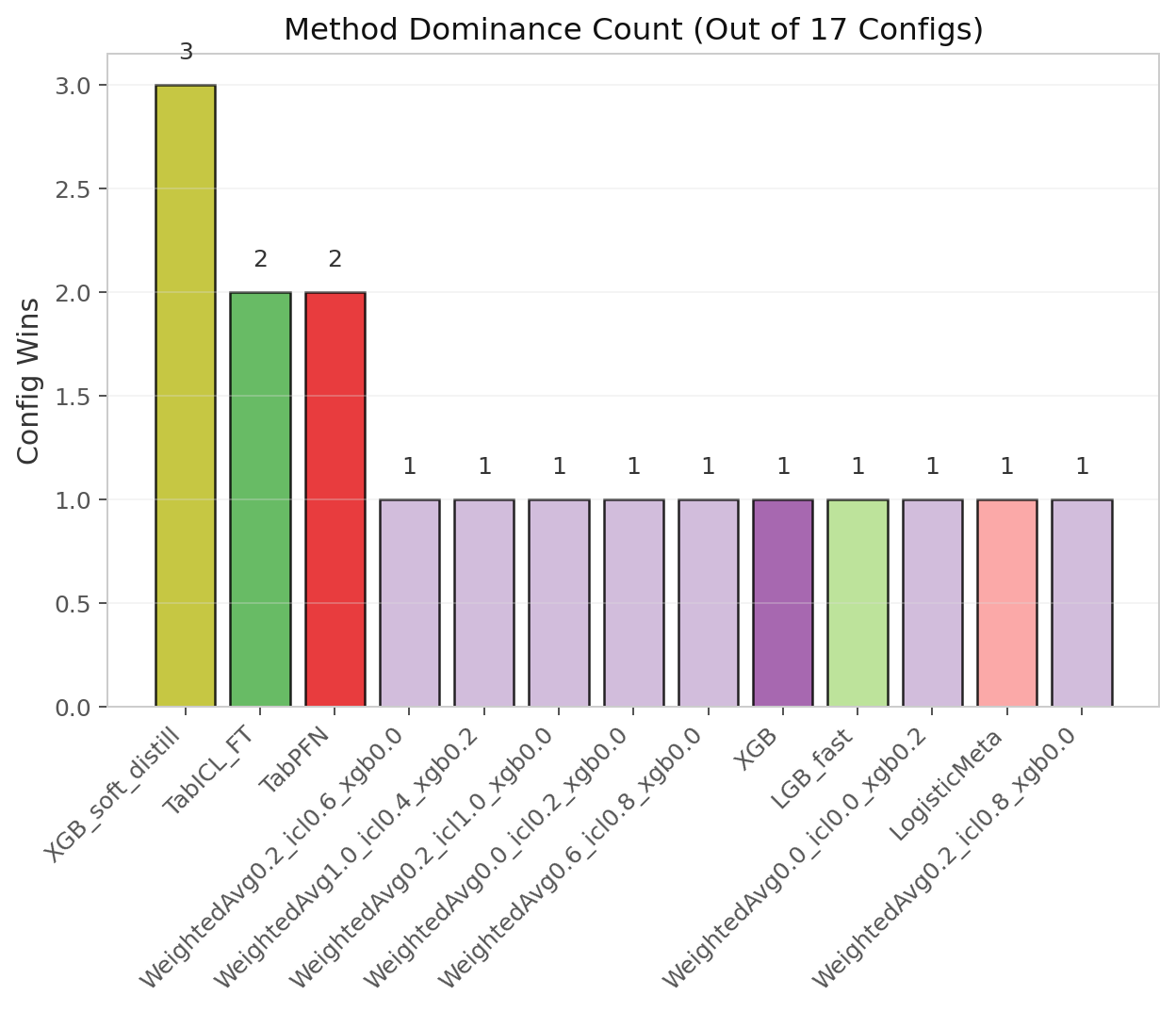
Figure 8: Number of configurations (out of 22) where each method family achieves the highest AUC. LGB_fast and XGB_default each win 3 configs when excluding the overfitting WeightedAvg family.
8. What We Actually Learned From The Supplementary Experiment
After locking the initial sweep, we realized we had no apples-to-apples comparison for soft distillation across booster families. We patched the benchmark to add CB_soft_distill_pfn, CB_soft_distill_icl, LGB_soft_distill_pfn, and LGB_soft_distill_icl.
This was harder than expected. Both CatBoostClassifier and LGBMClassifier crash on continuous soft labels with opaque errors about “Target with classes must contain only 2 unique values” and “Unknown label type: continuous.” The fix is to switch to regressors (CatBoostRegressor, LGBMRegressor with RMSE loss) and manually clip predictions back to $[0, 1]$. In practice, CB-soft and LGB-soft minimize
$$ \mathcal{L} = \frac{1}{N}\sum_{i=1}^{N} \bigl(P_{\text{teacher}}(y_i=1 \mid x_i) - \hat{y}_i^{\text{student}}\bigr)^2 $$
with $\hat{y}_i$ clipped to $[0,1]$ at inference. Soft distillation is therefore not a generic “train any classifier on pseudo-labels” technique — the API ergonomics vary wildly by library.
Results from the corrected sweep are rolling in now. On ieee-cis N=5k (the medium-scale sweet spot where soft distillation previously won):
| Method | AUC | Δ vs XGB_default | Δ vs XGB_soft_pfn |
|---|---|---|---|
| LogisticMeta_5 | 0.8535 | +0.0153 | +0.0097 |
| CB_soft_distill_icl | 0.8451 | +0.0069 | +0.0013 |
| CB_soft_distill_pfn | 0.8441 | +0.0059 | +0.0003 |
| XGB_soft_distill_pfn | 0.8438 | +0.0056 | — |
| LGB_fast | 0.8429 | +0.0047 | −0.0009 |
| XGB_fast | 0.8425 | +0.0043 | −0.0013 |
| LGB_soft_distill_pfn | 0.8297 | −0.0085 | −0.0141 |
| LGB_soft_distill_icl | 0.8250 | −0.0132 | −0.0188 |
Observations:
CatBoost soft distillation works. CB_soft_distill_icl edges out XGB_soft_distill_pfn by 0.0013 AUC — basically a tie. CatBoost’s ordered boosting seems to handle soft targets about as well as XGB’s gradient boosting.
LightGBM soft distillation is weak at N=5k. Both LGB soft variants underperform raw XGB_default on this single data point. Whether this is a general property of leaf-wise trees on noisy continuous targets, or merely a hyperparameter sensitivity (our LGB regressor used max_depth=6, same as the classifier), awaits the full sweep. We suspect leaf-wise growth may be less stable on soft targets than XGB/CB’s level-wise approach, but this is a hypothesis, not a conclusion.
LogisticMeta still wins. Even with the new contenders, stacking five base models beats every single-model distillation approach. The ensemble effect dominates the distillation effect.
Teacher-as-feature is scale-dependent. At N=5k, CB_teacher_as_feature achieves 0.8431 AUC — not a catastrophe. Why? Because the teacher itself is stronger at this scale (TabPFN 0.8539, TabICL 0.8593). When the teacher is decent, its predictions are less poisonous as features. At N=20k, where TabPFN collapses to 0.6924, the same technique drops to 0.3429.
The full supplementary sweep (ieee-cis 1k/20k, fraud-detection 500/2k/full) is still running. We will update this table when complete.
9. Conclusions & Recommendations
The central finding is not that soft distillation is magic. It is that foundation models fail catastrophically on high-dimensional, heavily-engineered fraud data, and fast gradient boosters are the correct tool. Soft distillation is a useful but non-essential refinement — the real win comes from choosing the right model family for the data distribution.
If you are building a fraud detection pipeline today, the evidence says: start with a shallow XGBoost, add a CatBoost for diversity, stack them with logistic regression if you have the latency budget, and skip the transformer unless your dataset is tiny or your features are pristine.
10. Raw Data & Reproducibility
- All 22 JSON result files: v4_raw_results.zip
- Benchmark script:
fraud_benchmark_v4.py(airig:~/tabpfn-playground/) - Analysis scripts:
v4_generate_plots_v2.py,v4_deep_analysis.py— available on request - Hardware: All times are wall-clock on RTX 5090. CPU-only TabPFN/TabICL fits will be slower.
- Random seeds: 42, 43, 44. All reported means ± std are across these three seeds.